SEO Process: How To Extract + Map Gemini 3 Fan-Out Queries
 I’m pretty excited for this article. After reviewing a couple processes with my co-founder Jason Melman, we’ve discovered a pretty easy way to help websites understand their coverage for query-fan outs.
I’m pretty excited for this article. After reviewing a couple processes with my co-founder Jason Melman, we’ve discovered a pretty easy way to help websites understand their coverage for query-fan outs.
So previously, we did some analysis on Google’s fan-out queries. We extracted 60K+ fan-out queries and looked to understand common patterns and how it worked.
Well one of the key things we found was that Google uses an average of 9-fan out queries for every one prompt. For one prompts, there actually be up to 28 different fan-outs. This distribution helps visualize it a lot better.
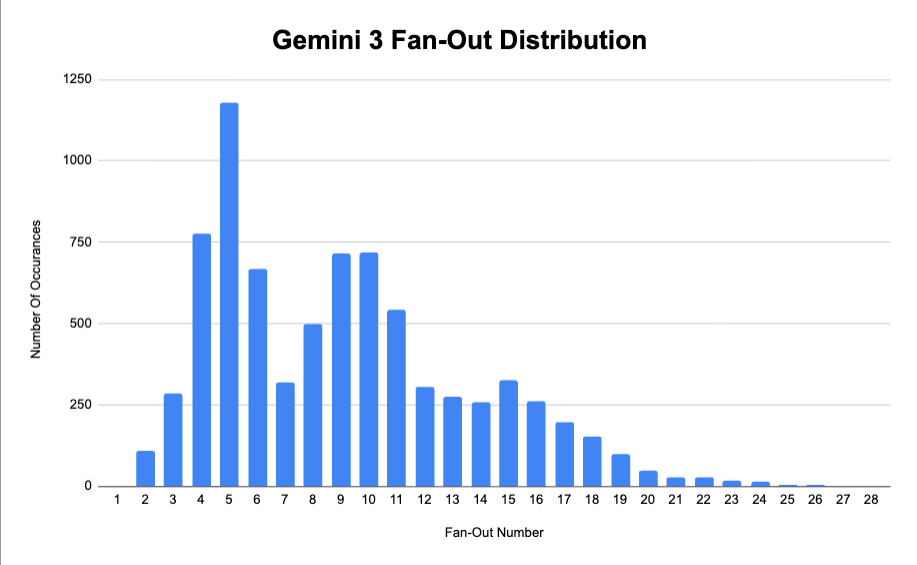
So that means for every 100 prompts you’re tracking – there is an average of 900 different “queries” associated with that. As you can imagine, that makes the search ecosystem INCREDIBLY COMPLEX. The amount of queries you need to account for in AI gets exponentially higher
So How Can You Map All Of Those Fan-Outs To Your Site?
In this article I’m going to show you how to do that using the Gemini 3 API and our Domain Coverage Analyzer tool.
P.S. If you’d like us to perform this type of analysis on your behalf with a larger dataset, please reach out!
What Are Query Fan-Outs?
So one of the fundamental ways that AI is going to change the SEO landscape is the concept of query fan outs. In case you’re not familiar, query fan-out is a process that many AI engines perform that search for multiple queries at a time instead of just one. Here’s a screenshot from Liz Reid’s 2025 Google I/O keynote that visualizes this process a bit.

So instead of optimizing for a single query at a time, you need to optimize for multiple. This creates a much more complex ecosystem to account for as you need to ensure you have content spread across all the permutations of the fan-out queries that AI engines could search.
Fortunately, we’ve already done a lot of research on this. The team at Nectiv has provided analysis on query fan-out data for both ChatGPT and Google (Gemini 3 which powers AI Mode). I highly recommend you read through those articles but two of the key takeaways for each are:
- ChatGPT averages 2 fan-out queries
- Google Gemini averages 9 fan-out queries
- There’s quite a bit of overlap in the terms both systems use
So the key things we need to understand are:
- Which queries are being used for fan-outs?
- Do we have content on our site that covers those queries?
I’ll walk through the process of how to do that with the Gemini 3 API + Nectiv’s Domain Coverage Analyzer.
Step 1: Extract Query Fan-Outs Via The Gemini API
First, we need to extract the fan-out queries at scale for a given prompt set. I’m going to assume you already have a prompt set because building one is an entirely separate article.
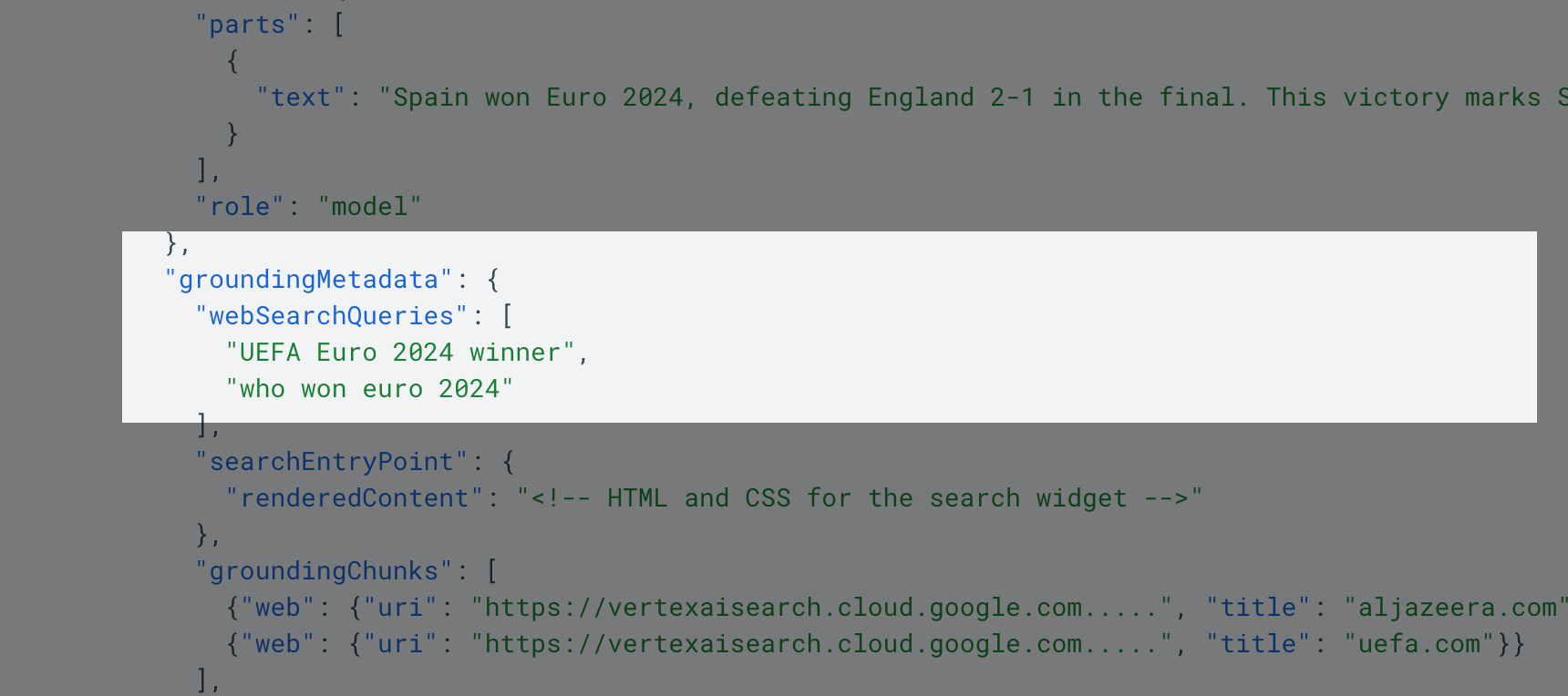
In order to get the fan-out queries, we’ll want to use the Gemini 3 API. Google actually has entire documentation around this that shows how you can use Python/REST in order to extract the data. In the output, you’ll actually get “webSearchQueries”. That’s the fan-out query data we want to extract from the API.
Full transparency, is that we used Claude Code to build this solution for our team. It’s unmatched at creating and autonomously debugging/iterating until it comes up with a working solution. However, I was able to use ChatGPT to create this Python script that did work:
import csv
import os
import time
from typing import List
from google import genai
from google.genai import types
# =========
# Config
# =========
API_KEY = os.getenv(“GEMINI_API_KEY”, “Your_API_Key“)
INPUT_FILE = “prompts.txt”
OUTPUT_FILE = “prompt_websearch_queries.csv”
MODEL_ID = “gemini-3-pro-preview” # or: “gemini-3-flash-preview”
# Initialize Gemini client + Google Search grounding tool
client = genai.Client(api_key=API_KEY)
grounding_tool = types.Tool(google_search=types.GoogleSearch())
config = types.GenerateContentConfig(tools=[grounding_tool])
def _dedupe_preserve_order(items: List[str]) -> List[str]:
seen = set()
out = []
for x in items:
if x not in seen:
seen.add(x)
out.append(x)
return out
def extract_web_search_queries(prompt: str) -> List[str]:
“””
Extract the web search queries Gemini 3 executed when Google Search grounding is enabled.
The API returns these in groundingMetadata.webSearchQueries
(Python SDK: candidate.grounding_metadata.web_search_queries). :contentReference[oaicite:1]{index=1}
“””
try:
response = client.models.generate_content(
model=MODEL_ID,
contents=prompt,
config=config,
)
queries: List[str] = []
for candidate in (response.candidates or []):
gm = getattr(candidate, “grounding_metadata”, None)
if not gm:
continue
# Python SDK typically exposes snake_case:
# gm.web_search_queries
wsq = getattr(gm, “web_search_queries”, None)
if wsq:
queries.extend([q for q in wsq if q])
# Extra defensive fallback (in case of shape differences)
# Some representations show camelCase: webSearchQueries :contentReference[oaicite:2]{index=2}
wsq2 = getattr(gm, “webSearchQueries”, None)
if wsq2:
queries.extend([q for q in wsq2 if q])
return _dedupe_preserve_order(queries)
except Exception as e:
print(f”ERROR: {e}”)
return []
def main():
if not API_KEY or API_KEY == “YOUR_API_KEY_HERE”:
raise RuntimeError(
“Set your API key via env var GEMINI_API_KEY or edit API_KEY in the script.”
)
print(f”Reading prompts from: {INPUT_FILE}”)
print(f”Output will be saved to: {OUTPUT_FILE}”)
print(f”Model: {MODEL_ID}\n”)
with open(INPUT_FILE, “r”, encoding=”utf-8″) as f_in, open(
OUTPUT_FILE, “w”, newline=””, encoding=”utf-8″
) as f_out:
writer = csv.writer(f_out)
writer.writerow([“prompt”, “query_index”, “web_search_query”])
prompt_count = 0
total_queries = 0
for line in f_in:
prompt = line.strip()
if not prompt:
continue
prompt_count += 1
print(f”[{prompt_count}] Processing: {prompt}”)
queries = extract_web_search_queries(prompt)
print(f” Found {len(queries)} queries”)
if not queries:
writer.writerow([prompt, “”, “”])
else:
for i, q in enumerate(queries):
writer.writerow([prompt, i, q])
total_queries += len(queries)
f_out.flush()
# Optional: be polite to rate limits / spikes
time.sleep(0.1)
print(“\n” + “=” * 60)
print(“✓ Complete!”)
print(f” Processed: {prompt_count} prompts”)
print(f” Extracted: {total_queries} total queries”)
print(f” Saved to: {OUTPUT_FILE}”)
print(“=” * 60)
if __name__ == “__main__”:
main()
You’ll perform the following steps in order to execute this:
- Save the above script as “extractwebsearch_queries.py”
- In the same folder create a TXT file called “prompts.txt” and paste in your prompt data
- Grab a Gemini API key and paste it into the code
- Open your Terminal. Download the Gemini with pip3 install google-genai
- In Terminal, run the script with python3 extract_websearch_queries.py
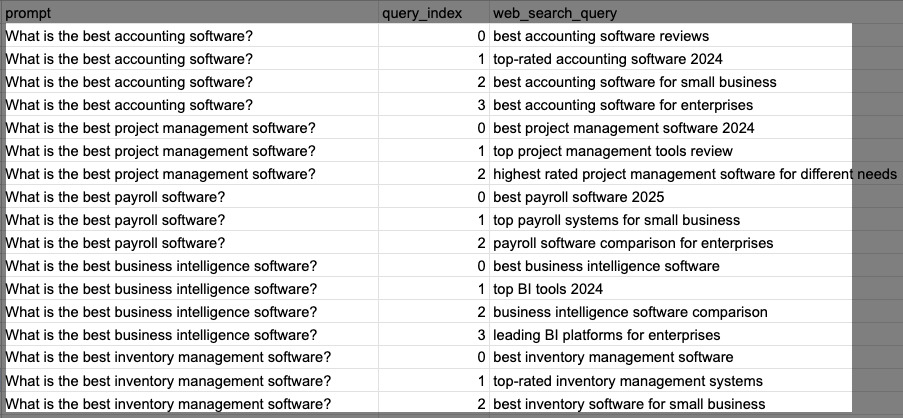
Once completed, you should have an output in a new spreadsheet. The spreadsheet should contain your prompts in the right column and all the associated fan-out queries from Gemini 3. You have now extracted your fan-out data at scale.
Step 2: Run This Through The Domain Coverage Analyzer
Now that we know the fan-out queries, you need to cross-reference this list with your site. The issue is that this can be quite difficult to do act scale. Depending on how many prompts you’ve run, you’ll probably have a larger list of fan-out queries. Reviewing each query manually would take an incredibly long time.
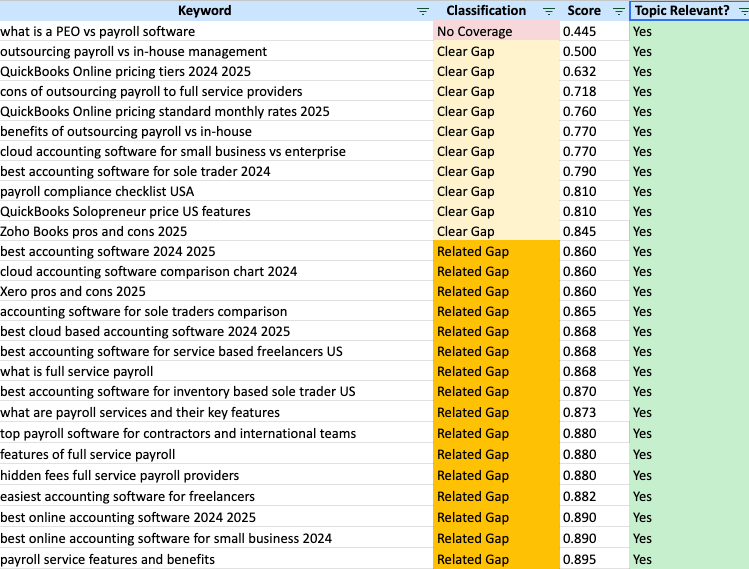
Fortunately, we have the perfect tool for this at SEOWorkflows.com. The Domain Coverage Analyzer allows you to insert a list of queries. If will then analyze the pages your site and find pages that map back to those queries. So it’s amazing for understanding if you have content that maps back to the core keyword.
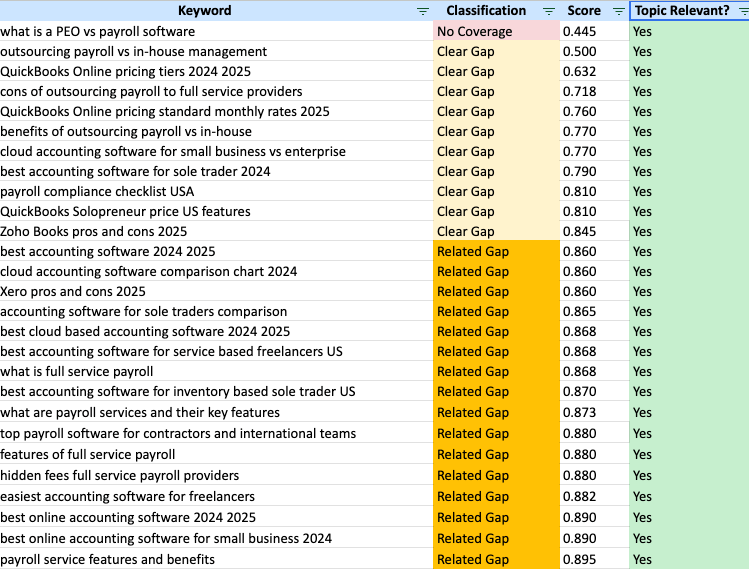
The Domain Coverage Analyzer will provide two sets of data that are key. If will identify assess whether each query is “Topic Relevant” to your brand. It will also give a “Classification” for each page in one of the four categories:
- No Coverage
- Clear Gap
- Related Gap
- Aligned
- Perfect Coverage
For the next step, take your queries from the Gemini 3 fan-out analysis and paste them in the Domain Coverage Analyzer. You’ll then get an output that maps each query to a page. In that output, I like to filter by opportunities:
- Topic Relevant = Yes
- Classification = No Coverage, Clear Gap, Related Gap
You’ll then get a spreadsheet that shows you individual fan-out queries that you might not have content for on your site.
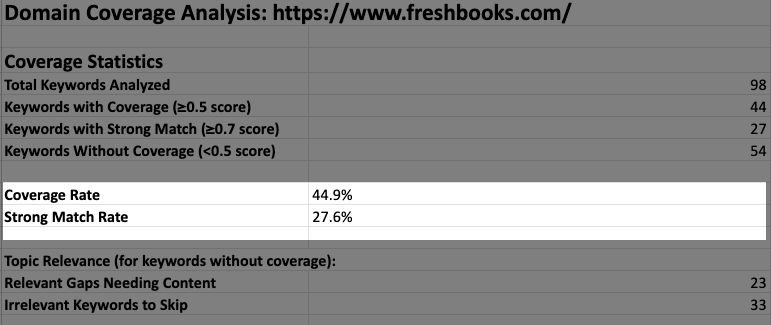
You can also look at the first tab which will give you a “Coverage Summary”. At a high level, you can see roughly how many of the fan-out queries you’ve provided content for.
Please note that the Domain Coverage Analyzer allows you to analyze 100 queries at a time. Many sites might need more scale than this. If you need this be adjusted or want a more custom analysis, shoot us a message here.
Conclusion
Hopefully this process is helpful to SEOs who are looking to better understand how well optimized their site is for Google’s fan-out queries. Once you’ve gotten things configured, you could scale this out to run across multiple different prompts to see where you site might have gaps in content coverage. You could then plan to ensure these opportunities into your content operations or optimizations strategies moving forward.